借助调试器快速理解代码
23 Nov 2018
长江后浪推前浪,前浪死在沙滩上。
这句话太适合形容IT行业了, 时髦的 技术/软件/框架 可能隔几年就被抛弃取代。
逼得咱程序员得不停地学习,停下来就意味着被淘汰。
大多数人聪慧程度一般,在完成一万小时定律之前,只能做技术的跟随者和使用者。
然而技术都有一定的学习曲线,好不容易掌握了还没耍几下,又要投入到下一波技术革新的浪潮中。
说白了就是熟悉的东西不搞了,要啃一堆堆新的代码,周而复始。
换组,换部门,换公司都会遇到上面的问题。
很快30岁就来了,似乎离“专家”还很遥远,您可能纳闷时间都去哪了?
如果您也有过这种烦恼,恭喜您成为本文重点阅读对象。否则请立刻关闭网页,无需往下浪费时间!
================================= 分割线 ================================
作为一个Developer,喜怒哀乐都来自一个抽象的东西: Source Code, 能搞得定它的就是大神!
Linus 大神说过 “Read the Fucking Source Code“, 但他没有具体指出用哪种方式,哪种工具来read?
总结我之前的read方式:
咨询同事,基本上也是用这套方式来read code,耗时很长。
实际开发过程中并没有这么充裕的时间来read code。
================================= 分割线 ================================
列举一个工作中常见的场景:
- 进入一个开发小组,任务是在某个软件模块的基础上开发一个新功能,要求时间越短越好。
- 进入模块学习阶段,此处省略XX字。。。
- 照葫芦画瓢,此处省略XX字 。。。 开发完成,进入测试阶段。
- 测试有bug,发现是新代码引入的,修。 又发现bug,再修。此处省略XX字。。。
- 测试还有bug,我去,此处省略XX字。。。最后发现是这个模块本身的bug!
- 研读代码 + 各种调试工具,此处省略XX字。。。终于搞定了。
- 换个小组/部门/公司,可能是不同的平台,不同的开发环境,跳转到第一步重来。
上面第2 ,第6步是耗时最长,最痛苦的。相信每个Developer都用身体会过。
若能快速跳过这两步,即快速理解代码,无疑是向大神靠近了一大步。
我相信大神都是有套路(方法)的,以不变应万变。
软件行业的万变在于有N个开发语言(C,JAVA,Python,..), N个开发平台 (Linux, Windows, Android, …),N个开发框架,N个 此处省略XX字 。。。
大神的不变在于找到一种通用的方式快速理解Source Code: (我个人观点)
-
工欲善其事,必先利其器。掌握 Source Code Editor, 达到如火纯青的地步, 有两种神器可选:
Vim:编辑器之神
Emacs:神的编辑器 (听名字应该选用Emacs ^_^)原因之一:它们适应万变,稍作配置即可支持另一种新开发环境。
原因之二:它们有无敌的扩展性,世界上没有一款软件能满足所有人的需求,每个人都是独一无二的,所以有独一无二的需求,可自行编写插件来实现。
原因之三:它们本身就是出色的软件,研究它,理解它,驾驭它,随心所欲地切换,思想流畅地从指尖流出,将生产力释放到极限,这是一种信仰。 -
相信最理解代码的是机器(CPU),最终运行的都是二进制,从程序运行的角度理解代码。
可以变相理解为让机器来read code,“监视”程序运行的每一步,将详细过程dump出来,再将这些数据转换成文档,告诉你代码长啥样。
Source Code 是源, 在机器上运行的二进制是尾, 抓住一头一尾。
此乃太极混元状态,一头一尾相系,一手一脚相合。此处省略XX字。。。好吧,我扯远了。
本文重点讨论第2点。
================================= 分割线 ================================
上面抛玉引砖这么多,进入重点环节。
本人声明: 如下观点如有雷同,纯属英雄所见略同。 ^_^
这里我选择调试器入手,原因在于:
- 最底层的CPU架构有很多种。
- 运行在CPU上的操作系统有很多种。
- 底层的调试技术(例如Linux的SystemTap)无法做到跨平台的通用。
而每种编程语言在每个平台上都有一套工具链,能帮住理解代码的就是工具链中的调试器。
这里我不用调试器来分析bug,而是找到一种方式来自动化控制调试器,让它将程序在运行时”走过的路程”都dump出来,
dump出来的数据越多好,越全越好。
回想下我们read code的过程中,不就是在脑子里生成这些”数据”么?再把这些数据总结成文档 + 流程图。
思考下:
- 我们总结的数据还有调试器dump出来的准么?
- 我们总结的速度还有调试器dump出来的快么?
再思考另外几个问题:
在比如你独自一人写了一个上万行代码的软件,过了一阵子再回想这些代码,每个细节都还清楚么?头脑里是不是只剩下代码大概的”运行过程图”?
是你更清楚代码还是正在运行这个软件的机器更清楚?
如果每个Developer都对代码了如指掌,运行的程序好比数学证明一样完美可靠,那还需要跑测试case干嘛?
如果程序有bug,就说明更懂代码的机器在告诉你: 你写的代码有问题,不是吗?
如果自己写的代码都不能了如指掌,更何况要理解别人写的呢?
OK,回到用调试器dump数据,这些数据比较原始,可读性/理解性不强,可以写个小程序稍微排版下,自动生成最终你想要的那张图或文档。
这个因人而异,反正就是你理解代码后头脑里存放的代码影相。 例如:流程图 / UML实例图 / 代码运行路线等等。
有了这些原始数据 + 排版后的数据,上面例举的工作场景里的痛点,就能迎刃而解。
例如:
-
4万行的strace源码,完全不用看代码就可以得到下图左边部分,运行过程一目了然。
对着排版后程序执行路线,稍微对应参照下源码,例如 ptrace_restart 执行的是 ptrace 系统调用,很快就能理解源码主要脉络。
详见: strace 源码分析 (快速分析源码,半小时搞懂)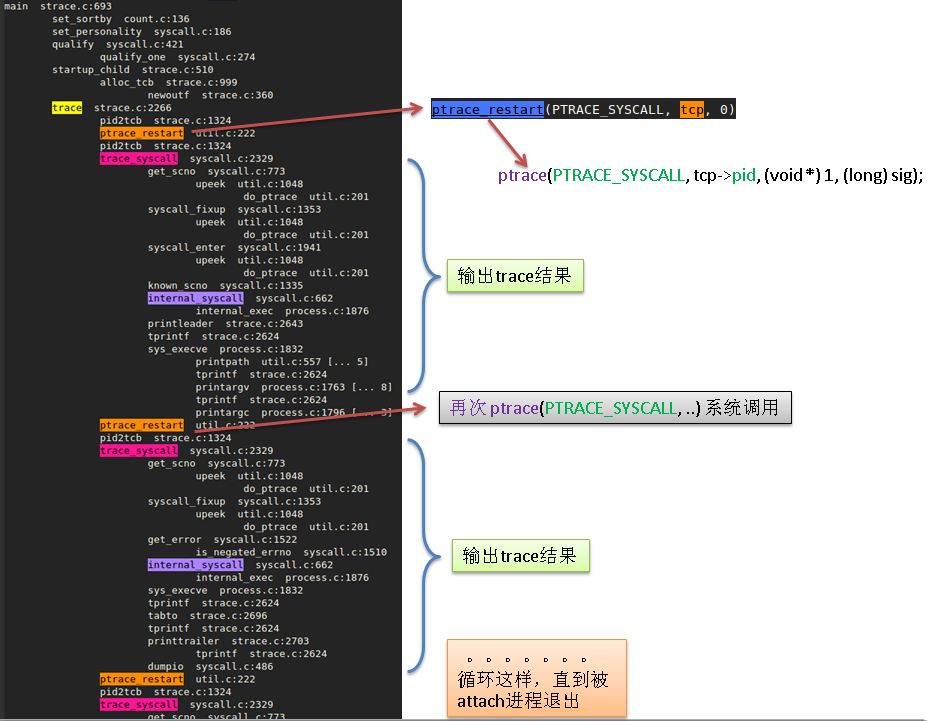
-
某老版本的linux kernel启动过程,不用看kernel源码。修改QEMU代码,将QEMU当成调试器,dump kernel运行状态,写个小程序排版下数据,输出路线图
详见: linux kernel启动 (自动化调试输出实例图)
================================= 分割线 ================================
下面举一个例子来实现我的“理论”。
例如想搞懂wget这个软件的代码实现:
$ nm wget | grep '[0-9a-z] [tT]' > wget.map $ cat gdb_wget.py
gdb.execute("set logging on")
gdb.execute("set height 0")
f = open("wget.map", 'r')
for line in f:
gdb.execute("b " + line[19:len(line)-1]);
f.close()
gdb.execute("run www.baidu.com");
while 1:
gdb.execute("bt");
gdb.execute("c");$ gdb ./wget | tee gdb.log
GNU gdb (Ubuntu 8.1-0ubuntu3) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./wget...done.
(gdb) source gdb_wget.py
...............运行结果见下图(1),左边部分,得到wget运行时执行到的所有函数及调用栈。
下图(2): 写个程序parse gdb.log, 得到可读性很好的程序运行路线。
下图(3): 在Emacs中折叠部分非重要函数调用过程,高亮显示重点函数,我相信一眼即可理解wget大致代码原理。
就算我死磕代码,花大量时间研究得很透彻,我相信过了一个多月,头脑里剩下保存的差不多也就图(3)显示的调用过程。
而用这种方法,整个过程不到5分钟。
如果要我在wget的代码上增加个新功能,我就顺着这些调用过程,在恰当的位置加些函数实现。
当然除了显示图(3)的样子外,还可以显示成类似UML格式的,只要有了原始的raw格式数据,即可将它们转成画图工具的输入数据,生成适合自己理解的图。
我收集的辅助画图工具:

================================= 分割线 ================================
对于其它语言同样需要找到能控制调试器的方法,以Java为例:
public class Test {
public static void main(String[] args) {
onesInByte();
}
public static void onesInByte() {
}
}stop in Test.main
stop in Test.onesInByte
run Test
cont
cont可以写个程序得到java class文件的所有方法,打上断点,并控制输入操作达到自动化
jdb详细命令见: https://docs.oracle.com/javase/7/docs/technotes/tools/solaris/jdb.html
我之前的一篇blog中分析 Android ArrayAdapter 界面创建流程,里面的调用栈就是用这种方法合成的,根据调用栈即可画出方便理解的流程图:
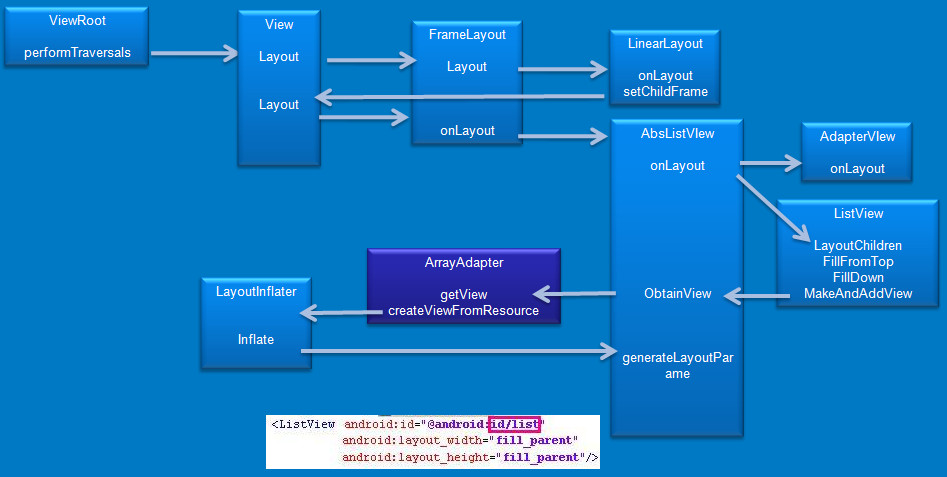
================================= 结尾 ==================================
用这种方法理解大多数用户态(应用)程序基本上没多大问题。
我遇到的不大适用的地方:
- 有些脚本语言调试功能较弱,不易生成调用栈。但此类语言大多用来写些辅助性的工具,代码量不算多。
- 函数式编程语言,如OCaml,对于lambda函数会在编译时生成匿名函数,其函数符号名可读性很差,影响最后的整体理解。
那如何用这种方式理解底层代码呢,例如操作系统?
因为底层的CPU架构有很多种,可以借助QEMU,QEMU虚拟了各种平台的CPU指令,可以把QEMU当成调试器,就很容易“追踪”底层的代码了。
再以大神的另一句话结尾吧。
“You can use a kernel debugger if you want to, and I won’t give you the cold shoulder because you have “sullied” yourself.” – Linus Torvalds
貌似大神比较鄙视使用调试器,OK 此方法姑且算是一种奇技淫巧吧,蝌蝌 ~