Qemu分析 -- 06 (用户模式内存映射)
14 Feb 2016
用户模式的qemu执行文件 qemu-i386, 可以直接执行target的目标代码,无须模拟target的整个硬件环境。
这里就有个疑问了,qemu-i386有main函数,target的目标代码也有main函数,一般ELF格式的的可执行文件的main函数线性地址都是一样的。
举个例子吧,运行 qemu-i386 /bin/ls, 这两个文件都是要运行的,那两个文件对应的main函数的地址,也就是对应的代码段,数据段怎么分开来的呢?
用file看下,果然,qemu-i386是ELF shared object, 而不是常见的ELF excutable

下图是qemu执行简单的~/test/simple可执行文件。
在执行期间,可以通过/proc/pidof qemu-i386/maps 看到在qemu-i386和simple在内存中的映射,~/test/simple被映射到了kernel默认开始执行的地址空间0x08048000:
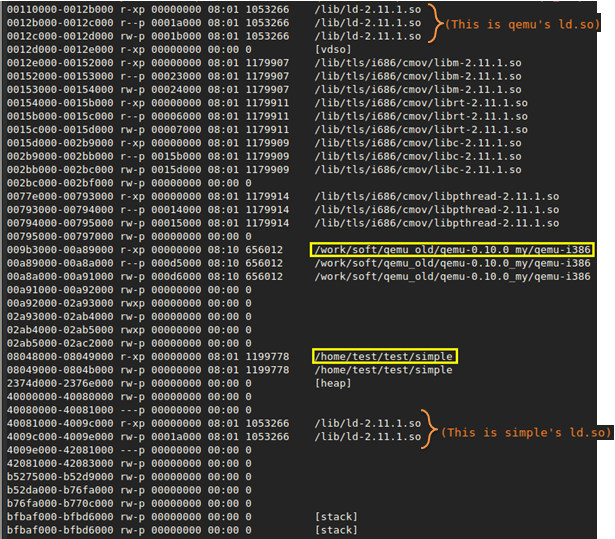
然后qemu-i386通过动态翻译,逐步将~/test/simple的代码段指令翻译成host指令并执行。
OK,再看下qemu-i386是如何完成这个映射的。
qemu内部模拟了x86 CPU的分页模式,
// exec.c
#define L1_SIZE 1024
static PageDesc *l1_map[L1_SIZE];
size_t len = sizeof(PageDesc) * L2_SIZE; // L2_SIZE = 1 << 10 = 1024
/* Don't use qemu_malloc because it may recurse. */
p = mmap(0, len, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
这样来看,整个4G的内存可以由两级页表指针所管理,
第一级有1000个指针,每个指向4M内存,
第二级也是1000个指针,每个指向4K内存。
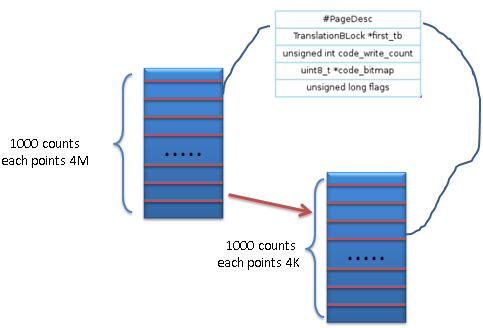
上面图中的每个格子都是一个struct PageDesc, 其大小sizeof(PageDesc) = 16, 所以, 对于这个两级指针,结构体本身需要的内存 = 1000*16 + (1000*16)*1000 = 16K + 16M
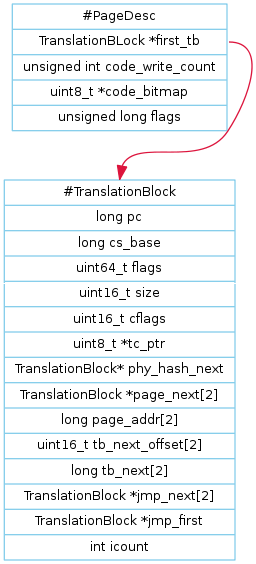
画出PageDesc的结构体,可以看到,每个页表指针其实都指向了一个Translation Block, 即翻译块,也就是目标代码块。 如果做好了目标文件在内存中的映射,说白了,就是将目标文件的地址映射在这个两级页目录结构体中, 那么qemu根据目标文件的地址找到目标代码在哪个页表也就很容易了。
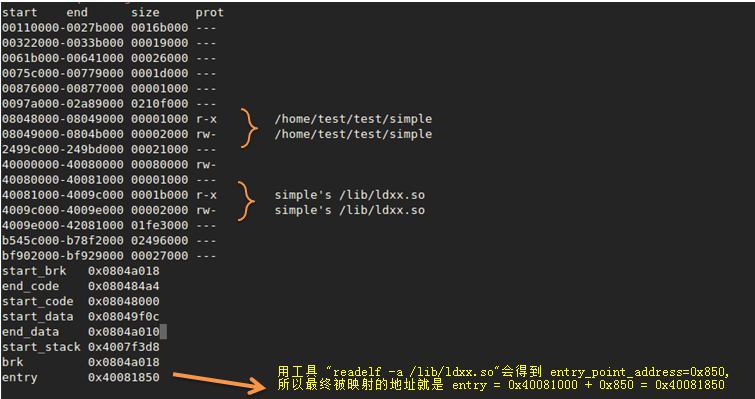
然后,打开qemu的debug选项,运行输出~/test/simple的映射, 计算出~/test/simple 应该被执行的第一条执行地址是0x40081850,对应的就是libc里面的_start, 从这开始目标文件~/test/simple就开始被翻译执行了。
上篇:
Qemu分析 -- 05 (Tcg的作用域)
下篇:
借助调试器快速理解代码