Qemu分析 -- 02 (缓存命中及LDUB)
03 Jan 2015
Qemu自 0.10 版本后,使用了TCG 完成动态二进制翻译功能。
为提高运行速度,就得牺牲空间来换取时间,这里就用到了缓存。
与物理CPU内部的二级/三级缓存差不多, Qemu内部也提供了目标代码执行指令缓存。
设计思想就是每次在执行完TCG动态翻译后,将目标代码放到内存buffer里(当然大小是有限的),
下次在执行动态翻译之前,先查找有没有这些指令之前已经翻译好的,如果有,则无需再翻译,直接执行buffer里面的代码。
如buffer里面没有,就继续动态翻译。就是我今天要分析的ldub_code, 动态代码合成。
Fabrice Bellard 把代码写得很巧妙,借助编译器生成源码,再编译成目标代码,这种方法,我要好好学下。

我再详细跟踪下第一条BIOS指令,Qemu是如何生成目标代码并执行的。
生成下面的调用栈有个小技巧:
先手动打上tb_find_fast断点,然后run,断点断住后,在gdb shell中执行source test.py,获取所有调用栈。
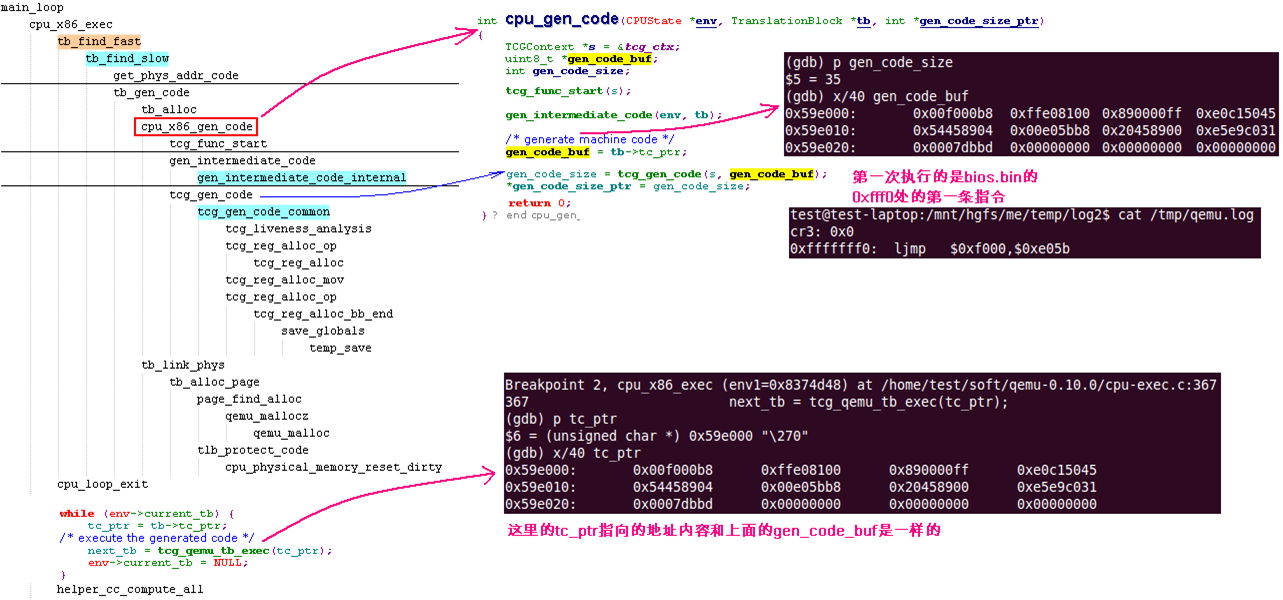
到这里,基本搞懂了Qemu是如何取指令,翻译成host指令,再执行的。